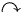
In the same time that PageRank was being developed, Jon Kleinberg a professor in the Department of Computer Science at Cornell came up with his own solution to the Web Search problem. He developed an algorithm that made use of the link structure of the web in order to discover and rank pages relevant for a particular topic. HITS (hyperlink-induced topic search) is now part of the Ask search engine (www.Ask.com).
One of the interesting points that he brought up was that the human perspective on how a search process should go is more complex than just compare a list of query words against a list of documents and return the matches. Suppose we want to buy a car and type in a general query phrase like "the best automobile makers in the last 4 years", perhaps with the intention to get back a list of top car brands and their official web sites. When you ask this question to your friends, you expect them to be able to understand that automobile means car, vehicle, and that automobile is a general concept that includes vans, trucks, and other type of cars. When you ask this question to a computer that is running a text based ranking algorithm, things might be very different. That computer will count all occurrences of the given words in a given set of documents, but will not do intelligent rephrasing for you. The list of top pages we get back, while algorithmically correct, might be very different than what expected. One problem is that most official web sites are not enough self descriptive. They might not advertise themselves the way general public perceives them. Top companies like Hunday, Toyota, might not even use the terms "automobile makers" on their web sites. They might use the term "car manufacturer" instead, or just describe their products and their business.
What is to be done in this case? It would be of course great if computers could have a dictionary or ontology, such that for any query, they could figure out sinonimes, equivalent meanings of phrases. This might improve the quality of search, nevertheless, in the end, we would still have a text based ranking system for the web pages. We would still be left with the initial problem of sorting the huge number of pages that are relevant to the different meanings of the query phrase. We can easily convince ourselves that this is the case. Just remember one of our first examples, about a page that repeats the phrase "automobile makers = cars manufacturers = vehicle designers" a billion times. This web page would be the first one displayed by the query engine. Nevertheless, this page contains practically no usable information.
The conclusion is that even if trying to find pages that contain the query words should be the starting point, a different ranking system is needed in order to find those pages that are authoritative for a given query. Page i is called an authority for the query "automobile makers" if it contains valuable information on the subject. Official web sites of car manufacturers, such as www.bmw.com, HyundaiUSA.com, www.mercedes-benz.com would be authorities for this search. Commercial web sites selling cars might be authorities on the subject as well. These are the ones truly relevant to the given query. These are the ones that the user expects back from the query engine. However, there is a second category of pages relevant to the process of finding the authoritative pages, called hubs. Their role is to advertise the authoritative pages. They contain useful links towards the authoritative pages. In other words, hubs point the search engine in the "right direction". In real life, when you buy a car, you are more inclined to purchase it from a certain dealer that your friend recommends. Following the analogy, the authority in this case would be the car dealer, and the hub would be your friend. You trust your friend, therefore you trust what your friend recommends. In the world wide web, hubs for our query about automobiles might be pages that contain rankings of the cars, blogs where people discuss about the cars that they purchased, and so on.
Jon Kleinberg's algorithm called HITS identifies good authorities and hubs for a topic by assigning two numbers to a page: an authority and a hub weight. These weights are defined recursively. A higher authority weight occurs if the page is pointed to by pages with high hub weights. A higher hub weight occurs if the page points to many pages with high authority weights.
In order to get a set rich in both hubs and authorities for a query Q, we first collect the top 200 documents that contain the highest number of occurrences of the search phrase Q. These, as pointed out before may not be of tremendous practical relevance, but one has to start somewhere. Kleinberg points out that the pages from this set called root (RQ) are essentially very heterogeneous and in general contain only a few (if any) links to each other. So the web subgraph determined by these nodes is almost totally disconnected; in particular, we can not enforce Page Rank techniques on RQ.
Authorities for the query Q are not extremely likely to be in the root set RQ. However, they are likely to be pointed out by at least one page in RQ. So it makes sense to extend the subgraph RQ by including all edges coming from or pointing to nodes from RQ. We denote by SQ the resulting subgraph and call it the seed of our search. Notice that SQ we have constructed is a reasonably small graph (it is certainly much smaller then the 30 billion nodes web graph!). It is also likely to contain a lot of authoritative sources for Q . The question that remains is how to recognize and rate them? Heuristically, authorities on the same topic should have a lot of common pages from SQ pointing to them. Using our previous terminology, there should be a great overlap in the set of hubs that point to them.
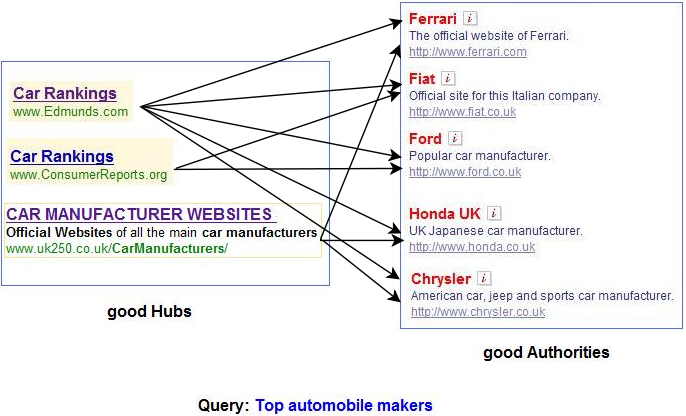
From here on, we translate everything into mathematical language. We associate to each page i two numbers: an authority weight ai, and a hub weight hi. We consider pages with a higher ai number as being better authorities, and pages with a higher hi number as being better hubs. Given the weights {ai} and {hi} of all the nodes in SQ, we dynamically update the weights as follows:
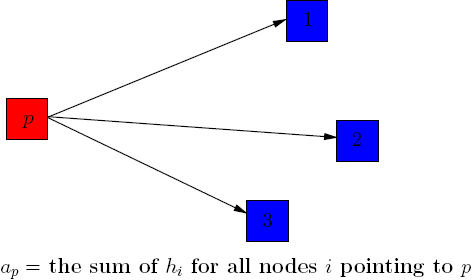
A good hub increases the authority weight of the pages it
points. A good authority increases the hub weight of the pages that
point to it.
The idea is then to apply the two operations above alternatively
until equilibrium values for the hub and authority weights are reached.
Let A be the adjacency matrix of the graph
SQ and denote the authority weight vector by
v and
the hub weight vector by u, where
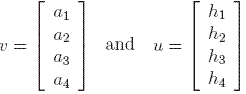
Let us notice that the two update operations described in the
pictures translate to:
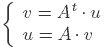 .
.
If we consider that the initial weights of the nodes are 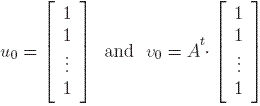 then, after k steps we get the system:
then, after k steps we get the system:
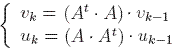 .
.
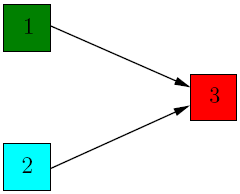
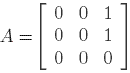 ,
with transpose
,
with transpose 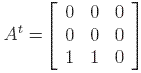 .
Assume the initial hub weight vector is:
.
Assume the initial hub weight vector is: 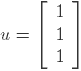 .
.
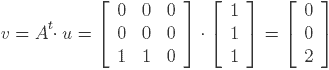
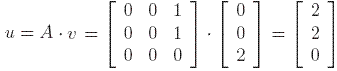 .
.
This already corresponds to our intuition that node 3 is the most authoritative, since it is the only one with incoming edges, and that nodes 1 and 2 are equally important hubs. If we repeat the process further, we will only obtain scalar multiples of the vectors v and u computed at step 1. So the relative weights of the nodes remain the same.
For more complicated examples of graphs, we would expect the convergence to be problematic, and the equilibrium solutions (if there are any) to be more difficult to find.
So the authority weight vector is the probabilistic eigenvector corresponding to the largest eigenvalue of AtA, while the hub weights of the nodes are given by the probabilistic eigenvector of the largest eigenvalue of AAt.
In the background we rely on the following mathematical theorems:We use the notion of "convergence" in here in a loose sense. We say that a sequence of vectors zk converges to a vector v in the intuitive sense that as k gets big, the entries in the column vector zk are very close to the corresponding entries of the column vector v. Without going into the technical details of the proof, the power method works because we have only one largest eigenvalue that dominates the behavior.
HITS algorithm is in the same spirit as PageRank. They both make use of the link structure of the Weg graph in order to decide the relevance of the pages. The difference is that unlike the PageRank algorithm, HITS only operates on a small subgraph (the seed SQ) from the web graph. This subgraph is query dependent; whenever we search with a different query phrase, the seed changes as well. HITS ranks the seed nodes according to their authority and hub weights. The highest ranking pages are displayed to the user by the query engine.
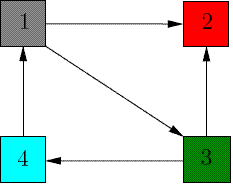
Hint: Compute the adjacency matrix A and show that the eigenvalues of AAt are 0,1, and 3. The normalized eigenvector for the largest eigenvalue λ = 3 is the hub weight vector. What can you say about the authority weights of the 4 nodes? Does this correspond to your intuition?
|
|
|
 Back
Back