In this episode Charlie uses some search algorithms to find crimes that are similar to a specific crime, so we'll discuss some abstract search algorithms and how they might be applied to finding crimes.
In this episode Charlie suspects that there is a seriel killer on the loose, and since serial killers often follow patterns, he wants to see if there are any unsolved crimes that match the patterns of the crimes he suspect the seriel killer has committed. This could be very difficult mathematically, so we'll break up the task into a few steps and talk about how some of the easier ones might work in general. Of course, for the specific application of trying to match crime patterns, there might be some specialized algorithms, but we won't talk about these.
Let's think about what it would take to get a computer to find crimes that are similar to some particular crime. First, you would have to find some way of telling the computer when two crimes are similar. This is difficult and depends strongly on what information one has about the crimes, so we'll discuss it very briefly at the end. Second, one would have to have an efficient way of searching through a large database of crimes to find ones that are similar. This could be tricky, so instead we'll describe some algorithms for searching a list of numbers to see if some particular number is in the list, and then we'll discuss possible ways to generalize this to find a number close to a particular given number.
First, let's think about looking for a word in a dictionary (which is basically the same thing as looking for a number in a list of numbers). How would you go about doing this? One way is to look through the dictionary in order, one word at a time, until you find the word you're looking for. This is obviously a dumb method because it would take a very long time and it doesn't take advantage of the fact that the words in a dictionary are in order. How long would this take? Well, if you looked up a whole lot of random words, on average you would have to look at half of the words in the dictionary for each word. So if there are N words in the dictionary, on average this method of search would take time N/2. This is a very long time.
A much better method is to open the
dictionary to the middle page. Then if the first word on that page is
later in the alphabet than the word you want, you can ignore the pages
in the second half, pretend that you have a new dictionary which is just
the first half of the original dictionary, and repeat. Otherwise, pretend
you have a new dictionary which is just the second half of the original
one. Now how long will this take, on average? Well, one way to answer
this is to figure out the maximum number of times that the dictionary
can be split in half. If there are N pages and
Now there's actually a subtle point in the last paragraph that we glossed over. Did you spot it? It's in the first sentence, when we said "open the dictionary to the middle page." To do this precisely, a human would have to search for the page, which would be inefficient. However, computers store lists in arrays, which allow them arbitrary access to elements based on their position in the list. So if the computer wants to access the element in position i, it can do so in one computational step, which means it can use the algorithm above exactly as described. If a person were to use the algorithm, they would have to replace the step "open to the middle page" with the step "open to approximately the middle page." However, this doesn't affect the algorithm or its efficiency significantly.
Now let's suppose that we have a list of numbers in random order. Is there any efficient way to search through this list? In this case, the only reasonable way to search for something in a randomly ordered list is to start at the beginning and go through the list one entry at a time. Just as before, if you're given a random number and the list has N entries, then on average it will take you N/2 tries to find the number. Also, if you had M different numbers that you wanted to search for, this would take M*N/2 tries, on average. If M is a large number, then this is very inefficient. How could we make this more efficient? One way is to take the list of randomly ordered numbers and sort it so that we can use the algorithm described above. Then after the list is sorted, performing M searches will take approximately M*log_2(N) tries, which is much more efficient.
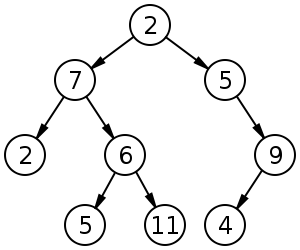
Now we'll talk a little bit about a more advanced method for storing data that will make it easier to find numbers in a list that are close to a certain number. The data structure that we were using before was just a list of numbers, which we can picture as being on a line. However, we can also use a "2-dimensional" data structure called a tree. A tree is a special type of a graph, which have been discussed in other Numb3rs episodes. A tree is a collection of some nodes, and each node contains a piece of data (a number, a word, etc.) and links to its children. We can picture a tree as having multiple levels. On the first (top) level, there is one node called the root. It has links to one or two children, which are on the second level, and it doesn't have a parent. The children of the root each can have 0, 1, or 2 children themselves, and they can have children, etc. The picture is an example of a unordered tree, where there doesn't have to be any relationship between the parent's data and its children's data (in the picture the data that each node stores is a number). However, the type of trees that are useful for searching are ordered trees, where for each parent, the number in the left child is less than the number in the parent, which is less than the number in the right child. Now if you wanted to search for numbers in a list which were close to a particular number, you could put the list into a tree and then perform a search for that number. Even if you don't find that particular number, you will end up finding numbers that are close to that number in the list.