While investigating a major meth laboratory, Charlie and Megan recover a hard drive belonging to the primary meth distributor. Unfortunately, the disk had been badly damaged by the explosion of the meth lab. In spite of that - and luckily for the investigators - in many cases it is still possible to recover data on a badly damaged drive by making use of a computer's built-in redundancy in data. Essentially, even large portions of the files on a drive are lost or erased, because of symmetry and redundancy in most modern data storage, Charlie had a chance!
Why would computers need to have these built in "double" (or more) storage of files? How do they do it? (As a hint, it's rare to just have multiple copies of a file as the safety measure!) What other devices or technologies use this "error control"?
Most of these have their answers in "coding theory" or "information theory," a relatively modern set of ideas beginning largely with the work of Claude Shannon in the late 1940's - and now you too will get a chance to see how (and why) these "error control/prevention" strategies were developed!
Say you are an astronaut wanting to transmit a signal from your space station back to mission control on Earth. You'll be broadcasting from hundreds of miles above Earth, through solar radiation and electromagnetic disturbances, through atmospheric effects, cloud cover, and amidst the millions of other signals that are being sent all across Earth. How can you make sure that all (or even a large part) of your message makes it to mission control?
Let's assume that you've already translated your message into binary from the start, as it's easier for machines to send and receive. We're going to want to somehow augment or change our message in such a way that we can send it, possibly lose or damage a part of it, then on receiving this new damaged message, either detect the error, or even better, correct the errors and losses back to our original message.
Scheme 1:
Let's say we have our message, perhaps:
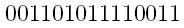
Before your transmit your message, count the number of 1's in it. In this case, there are nine 1's. If you had one more 1 to the end of the message, we have a new message
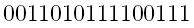
with ten 1's.
Now there are an even number of 1's. If mission control receives your message with any one error (let's say we put them in the 3rd spot and the 7th spot, respectively,) giving us a pair of messages something like
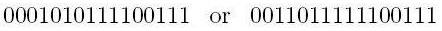
Mission control, upon receiving these, knows that there SHOULD be an even number of 1's. However, as they only see an odd number of 1's, they know there must be a mistake.
If instead, you'd wanted to send a message like
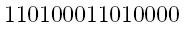
which has an even number of 1's already, we'll add a 0 to the end, so again, any one error (or any odd number of errors) will let mission control know something is amiss.
Scheme 2:
First, we'll need a definition. Let
x and
y be words in {0,1} of length k (i.e. they are strings of 1's and 0's of length k.) We say that the "Hamming distance" between
x and
y is the number of places where they differ. For example, 01100011 and 11101010 have a Hamming distance of 3 from each other, while 01100011 and 01101011 have a Hamming distance of 1.
Now this next bit is a little tricky - we need a way to take our message
x and translate it into a "codeword"
y so that when
y is transmitted, if we have d errors in the transmission, we can either detect the error and resubmit the message - or better yet, we can automatically correct to the
right codeword
y. After we correctly received (or fixed)
y, we should then have a way of translating
y back to our real message
x.
If we want to correct up to d errors (for a fixed d>0), what we really need then is a function from words (messages) of length k into the set of all words (codewords) of length n>k (for a fixed n.) This function needs to satisfy the property that any two distinct message words will be mapped to codewords that have a minimum Hamming distance from each other of at least 2d. That way, if we have an unencoded message
x, which we encode to
y, even if we have up to d errors, only that ONE code word corresponding to
x will be "close enough" (Hamming distance wise) to be the right one. We call codes of this form "Hamming Codes".
If we can do this, it'll be a real improvement. Before, we could only detect d errors if d was odd, and even then, we had no way of fixing our word!
Where to start though? Well, here's a sample set of code words of length six, and a map from our "message" words of length three to our code words.

Note that ALL possible words of length three are possible message words - but not all words of length six (how many words of length six are there?) are present. Note also that each codeword is at least Hamming distance three from every other codeword - so if we have 1 error or 2 bit erasures, we will still be able to figure out which
real codeword (and hence, which message word) our received word corresponds to! Let's test this.
 Activity 2:
Activity 2: With a partner, try the following:
- Each of you should take a message word of length 3, then look at the codeword that message word corresponds to. Write it down, so the other person can't see. Now, change the word at one place. Pass the new word to your partner, and see if they can figure out from the list which message must have been transmitted. Repeat, but this time, try erasing two spots and see if they know what word it must be.
- Discuss with your partner why you can't change two or more spots or erase three or more spots and still be able to figure out the correct message word.
Scheme 3:
This new code will be a special kind of the previous code. All we required previously was that our code map message words onto codewords in a way that separated each codeword by some fixed Hamming distance. It didn't say that there had to be an easy way to either encode, error check, error correct, or decode! If we have message words of length k, if our code is just random, we will have to store 2^k different codewords to even be able to encode a message. The code used in CDs for example takes message words of length k=224 and encodes them into message words of length n=256 - so if the code was constructed as the one above, we'd have to store 2^224 code words, each of length 256! Even with efficient ways of looking up our words, we would have to store over 6.4x10^6 gigabytes of information just to read our own code! [1]
One way to make it easier to encode words is by only considering linear codes - i.e. sets of code words that are closed under "addition" (we add at each place in the word, and note that 1+1=0.) If we have message words of length k, it is enough to pick k linearly independent codewords that form a basis for the set of all codewords and make those the rows of a kxn matrix. Here's a sample matrix for a code C with k=4 and n=7:

Given a message word
x of length k=4, we multiply it by our matrix G and look at the output vector
y. This is our codeword! Here's a partial list of our codewords, along with their corresponding message words:

Activity 3:
- Fill in the last four rows of the table above. Remeber 1+1=0, and we don't "carry" to the next slot.
- Check that the distance between codewords is 3. (If this is too tedious, just check that the distance between all of the first six codewords is at least 3.)
- Write down five random strings of 0's and 1's of length seven. Check if any are codewords. If they aren't codewords, how far are they from a codeword? Make a hypothesis, then prove it using a counting argument if you can. If you get stuck or think you have an answer, read on!
You may have noticed in doing the third part of the last activity that any word you chose was either a codeword already or distance 1 from a codeword. The "spheres of radius 1" around our codewords must include our entire set of words of length 7! How can we prove this?
Note that if we fix our codeword
x, there are seven words around
x at distance 1 from it - namely, if we change the digit in any of the seven slots, we will have a new (unique) word at distance 1 from our original word. Including our codeword itself then, there are 8 words in each ball of radius 1 around our codeword. By direct examination, we see that there must be 16 codewords (as there are 2^4=16 message words of length 4.) So we have 16x8=128 words in the balls of radius 1 around our codewords - and as there are only 2^7=128 total words, we are done.
This is an example of something called a "perfect code". There is an infinite family of such codes containing this one, with parameters n=2^r-1, k=2^r-r-1, and d=3 for all r greater than or equal to 1. Think about how you would construct them for a while. Can you generalize our G?
Reed-Solomon Codes
The next type of codes to really understand are called Reed-Solomon codes, which are linear, cyclic, and much easier to work with. To discuss them though, a decent background in the construction of finite fields, the division algorithm, and algebraic geometry is necessary. These codes are frequently implemented, as they are easily encoded, corrected, and decoded. To read more about these - the next step in error-correcting codes - check out
this site for a concise introduction. For the best introduction though, check out [1].
To actual decode this, we could use something called a "check matrix" such as in this case,
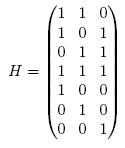
Our codewords are exactly those words
y for which
yH=0. If our codeword doesn't map to zero under parity check matrix H, we toggle the digits one at a time until we find our correct codeword. In this case, we can only correct one error, so there can be at most seven numbers we'd have to check before finding the right one.
Activity 4:
Here's a puzzle in two parts. The first part is easy enough without thinking about error-correcting codes, but think about them for a while when trying to solve the second part!
- Three people are sitting in a circle, and they'd like to play a game as a team. Each person has a hat, either black or white, the color of which he doesn't know at all. He can, however, see his neighbors' hats. The game is this: The men go around the circle and guess their own hat color OR they pass and make no guess. Nobody can hear another person's guess. The team loses the game if anyone guesses their hat color incorrectly OR if nobody makes a guess. There exists a strategy so that the team can win the game 3/4 of the time. Find it!
- Challenge Question: Our team is back again, but now instead of 3 people, we have 2^n-1 people, i.e 7, 15, 31, etc. Show that there is a strategy so the team can win
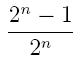
of the time!
References and Further Reading:
[1] D. Cox, J. Little and D. O'Shea, Using Algebraic Geometry, 2nd ed., Chapters 9 & 10, Springer, New York, NY. [[As a note, much of the material here has been adapted from the introduction to a set of notes given out at the Texas A&M Algebraic Geometry workshop and based on material in this book.]]
[2] R. McEliece and L. Swanson, Reed-Solomon Codes and the Exploration of the Solar System, Reed-Solomon Codes and their Applications, S. Wicker and V. Bhargava, editors, IEEE Press, New York, NY, 1994, pp.25-40.

