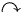The development of World Wide Web lead to a whole new field of mathematics called Internet Mathematics. It is a mixture of probability, linear algebra, graph theory and dynamical systems, designed to answer stringent problems about how information propagates over the net.
In the previous lectures you have seen how Google uses PageRank to determine the relevance of web pages, thus making Internet search simple and efficient. From a web designer's perspective, it is important not only to create a nice web site, featuring interesting graphical effects, but it is important what other pages link to your web site. A good PageRank can turn your business into a very profitable one. From Google's point of view however, it is important to keep PageRank computations accurate, and to prevent fraud attempts. Link spam is defined as the intentional attempt to improve the ranking of a page on the search engine, by increasing the number of pages that link to it. Link farms involve creating strongly connected communities of web pages referencing each other, humorously known as "mutual admiring societies". Although some link farms can be created by hand, most are created through automated programs and services. It is important therefore to recognize dense subgraphs of the web graph designed to do just that, and to eliminate them from page rank computations. Although at its core, Page Rank is as described in the previous section, in the real world, Google uses improved search algorithms to deal with these problems; these algorithms can assign different weights to outgoing links, or decide that certain links should not transfer page rank at all, to name just a few of the extra features. It is important to notice however, that as stated on Google's website, "while we have dozens of engineers working to improve every aspect of Google on a daily basis, PageRank continues to provide the basis for all of our web search tools".
Another research direction is the analysis and comparison of different ranking algorithms. One property that makes an algorithm good is stability. The World Wide Web is in constant change, pages are added and deleted at every moment. Stability measures how much rankings change if the Web graph is slightly perturbed. Ideally we would like the ranking algorithms to be stable so that, for instance, we would not have to constantly recompute the PageRank.
With a lot of interest coming from both mathematicians and computer scientists, understanding the structure of the Internet graph is a key research problem. Developing models for an Internet graph that has billion of nodes, is however far from being trivial. The web is often described as having a bow-tie structure. The knot of the bow-tie is represented by a strongly connected component of the graph, called the core. One side of the bow-tie consists of pages that link to the core, while the other side of the bow-tie contains pages that contain at least a link from the core. The rest of the web pages are either in disconnected components, or in tendrils that only link to pages outside of the core. In this spider net, social networks, web communities are defined as subgraphs with more internal links then external ones. Spectral methods are used to analyse the distribution of these communities.
Semi-random Internet topology. The Internet nodes are red dots and linkages are green lines.
Understanding the Internet graph can help answering questions about how information propagates over the net. Computer virus propagation over the net is of particular interest. Understanding the rate at which computer viruses propagate can help antivirus software makers to anticipate and quarantine infected areas.
Although in our previous lectures we only talked about finte graphs, we can also view the web as an infinite graph. The reason for this is that web pages are of two kinds: static and dynamic. Static pages contain information that remains unmodified. Dynamic pages are those built "on the spot", as a result of a query. For instance, if we do a Google Search with the phrase "mathematics and computer science", Google returns a page with relevant links and their descriptions. Of course, Google does not have a page prepared beforehand, for every possible query a random user might have. For every query it receives, it searches through its index to track the documents which contains the given search words, then Google runs the Page Rank algorithm to rank the relevant hits. Only after that, does it build up the answer to the user. We call such a page a dynamical page. While the number of static pages is finite (over 30 billion, but still finite), the number of dynamical pages is virtually infinite. Such a complete view of the web including both static and dynamic content can be given by infinite graph theory. The mathematics behind it is both interesting and challenging, and it is an ongoing research field.
The book "A course on web graphs" by Anthony Bonato and the online journal "Internet Mathematics" established in 2003, provide excellent sources of information on how mathematics improves our Internet experience. All the topics discussed above are covered in detail, with a lot of entertaining examples.
|
|
|
 Back
Back