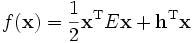
Edsger Dijkstra (1930-2002) was a Dutch computer scientist. He was instrumental in developing many of the ideas behind modern programming languages. Despite this, he is most famous for a relatively simple algorithm. Suppose we are given a graph G which is comprised of vertices V, edges E, and a weight function W. W takes edges as inputs and outputs a non-negative number. The usual interpretation of this scenario is that G is a map of highways: each vertex is a major city, each edge is a highway, and the weight of each edge is how long it takes to travel from one vertex to the other. Starting with a vertex s, Dijkstra's algorithm determines the weight of "lightest" path from s to every vertex in the graph.
The algorithm works as follows:
Basically, Dijkstra's algorithm starts with a vertex s. It then defines the set of available paths from s. To start, this includes only the adjacent vertices to s. It picks the shortest path among those. It then updates the list of available paths, then picks the shortest among them, and so on until every vertex has been reached.
By changing the algorithm to also keep track of the paths it adds, one creates a subgraph of G. This graph is called a rooted tree. The vertex s is the root, and edges branch out from it. The terminal nodes (those which are adjacent to only one vertex) are called leaves. In general, a forest is a graph which contains no cycles - a cycle is a path from x to itself which does not repeat any edges. A connected graph is one in which there is always a path joining any two vertices. A connected forest is called a tree.
An algorithm related to Dijkstra's algorithm is the Bellman-Ford algorithm. This answers the same question as Dijkstra except that the Bellman-Ford algorithm works on weighted digraphs which are weighted graphs where some edges may have negative weights. If one is careful, one can see that the worst-case number of steps required for Dijkstra's algorithm to complete grows about as quickly as V× E. The Bellman-Ford algorithm takes roughly V2 steps.
Charlie mentions the Frank-Wolfe algorithm. It is an algorithm which reduces a quadratic problem to a linear problem. The goal of the algorithm is to minimize an energy-like expression subject to linear contstraints, specifically
The algorithm is fairly simple, but involves some calculus of functions of more than one variable. In what follows, grad(f) means the gradient of f. The gradient of a function of one variable is just the ordinary derivative. For functions of more than one variable, it is a generalization of the derivative. The gradient of a function of n variables at a point is an n-vector which points in the direction in which the function increases most rapidly. A superscript T means that we take the transpose of the vector - all this means is that we take a column vector and write it as a row vector.